
好,我們現在已經很了解 Spotify 是怎麼蒐集、處理和儲存他們的用戶行為資料了。這些藏有珍貴價值的資料,如果一直放在儲存系統裡面,也是沒有辦法變成寶石和黃金的,他們非常渴望能夠被資料科學家挖掘。
而身為資料科學家,也一定非常想知道公司有哪些寶藏可以探索,只是 Spotify 的資料真的太多,一時半刻也很難知道整間公司到底有什麼樣的資料可以使用。
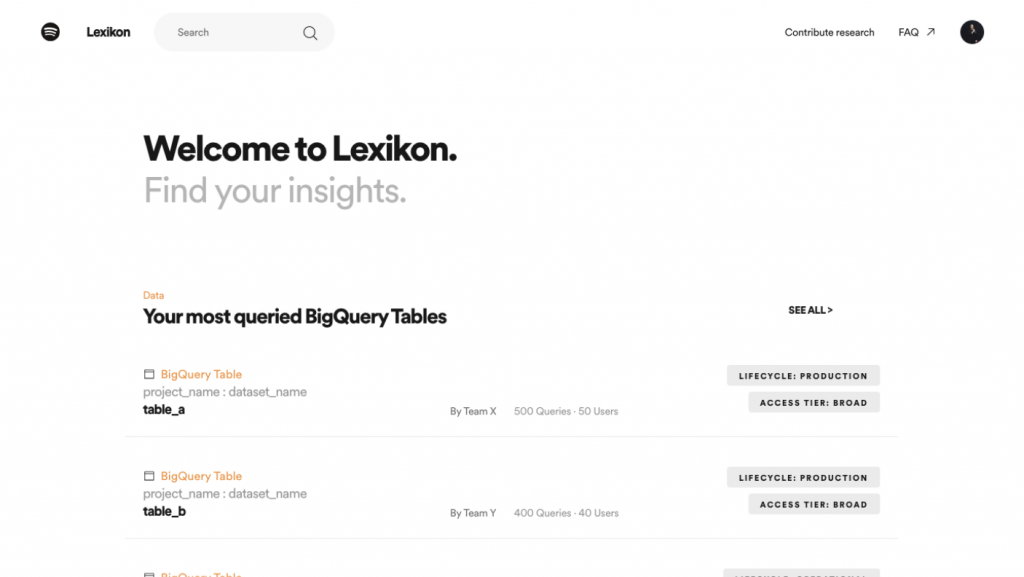
為了媒合資料本人跟資料科學家的需求,Spotify 推出一個資料搜尋平台——Lexikon,這個平台旨在幫助員工找到他們擁有的 BigQuery 表格(也就是資料集),並且同時呈現關於每個資料集的過往研究和分析,有助於內部使用者更理解公司有的資料,以及他們過去或是未來可以拿這些資料做些什麼應用。
不過,只是呈現公司擁有的資料集,以及曾經做過的研究分析是不夠的。不愧是身為音樂串流與推薦系統的龍頭,連在建立內部的資料搜尋平台時,都希望打造成有推薦功能的搜尋系統,讓資料科學家可以花費更少的時間,找到最適合使用的資料集。
看到這邊,你有沒有覺得 Spotify 真的是太強了,連打造內部系統都可以這麼用心,難怪可以坐擁音樂串流平台的寶座啊!
為了改善 Lexikon 的資料搜尋體驗,開發團隊進行內部的使用者調查之後,歸納出三個提升用戶體驗的方法:
圖片來源:[1]
Spotify 認為不同意圖的用戶,使用 Lexikon 的方式和目的也有所不同。
處於低意圖資料探索模式的資料科學家沒有特別想要找尋的資料集,例如 Spotify 的新進員工,或是想要開始一個新專案的員工,想要看看公司內部存在什麼有趣的資料集。
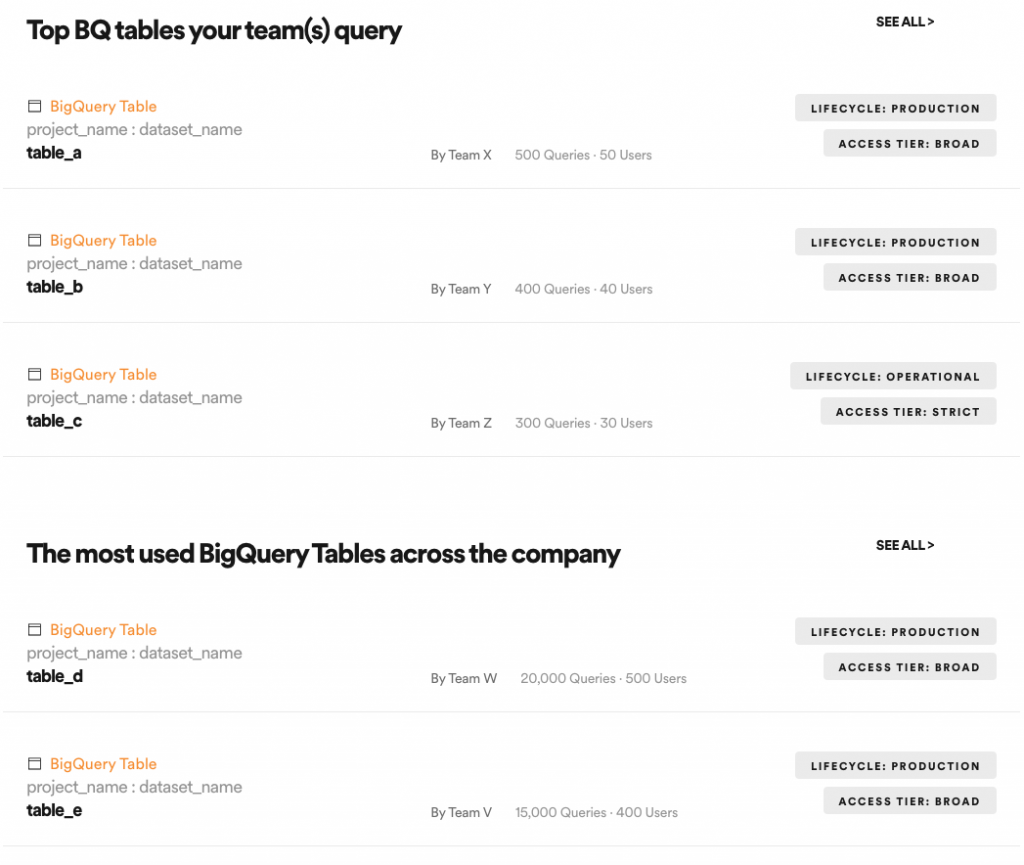
為此,Lexikon 團隊在首頁新增了幾個功能,如下圖所示
圖片來源:[1]
在改版之前,大部分的用戶都是使用 Lexikon 的搜尋功能,而在增加這些推薦功能後,有 20% 的月活躍用戶(monthly active users)改成直接使用首頁的推薦資料集,代表這些推薦內容是有效的!
Spotify 也有另外一群具有特定目標的使用者,很清楚自己在搜尋的內容,也非常熟悉當中的某些資料集。這群使用者需要被滿足的需求和前者有所不同,他們希望能夠
為此,他們提供了兩種方法:
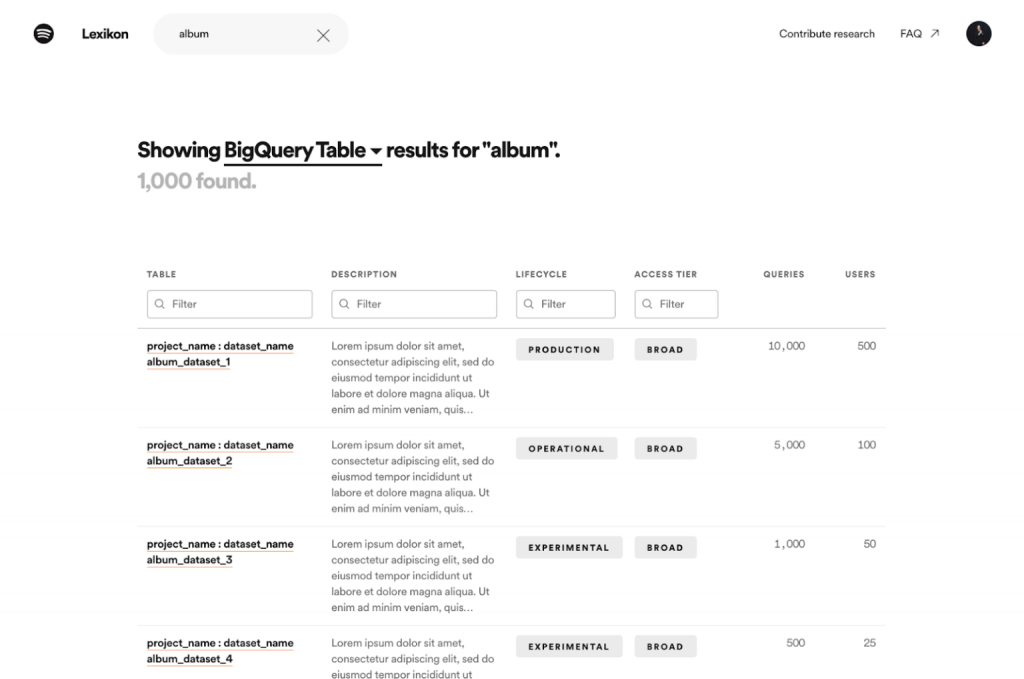
1. 搜尋排名演算法
經過數據分析後發現,雖然 Spotify 擁有成千上萬個資料集,但是大部分的使用量都在少數資料集上,而處於高意圖探索的用戶也通常在找這些資料集。因此,他們調整了搜尋算法,使搜尋結果會根據資料集的受歡迎程度而有不同的權重分配。如下圖所示,他們在陳列搜尋結果的同時,也顯示目前的 query 量和用戶數量。這個改變獲得用戶的讚賞,讓他們對於搜尋的結果更有信心。
圖片來源:[1]
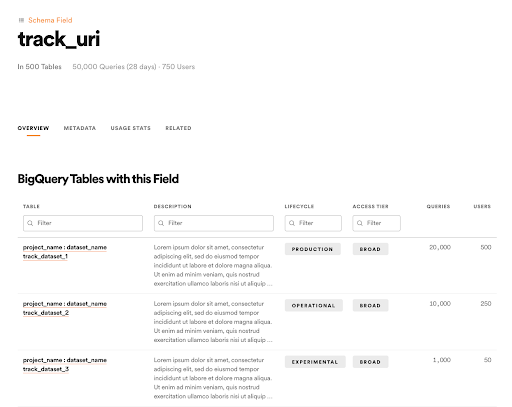
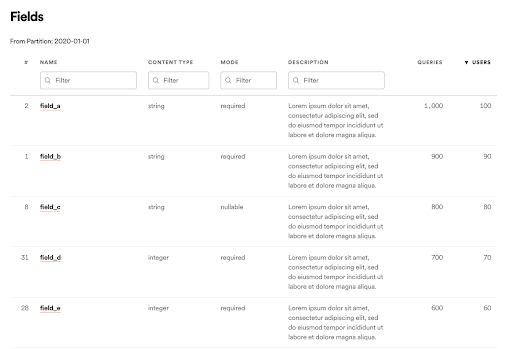
2. 增加新的實體(entities)
另外,他們在 Lexikon 顯示新的實體(如 schema field、專案、人員、團隊等),以更好地描述這份資料,讓搜尋變得更為容易。以下圖為例,如果用戶想要尋找包含「曲目 URI (track_uri) 」的資料集,也可以輕鬆找到相關內容。在推出這項功能之後,有 44% 的 Lexikon 月活躍用戶會使用這種類型的頁面。
圖片來源:[1]
有趣小補充,Spotify 在打造他們的音樂推薦系統時,也有對用戶進行過類似研究。
他們發現用戶在聆聽推薦的歌曲時,一樣分為低意圖和高意圖的用戶,而對兩種不同意圖的用戶而言,「跳過推薦歌曲」這件行為不一定總是負面的。對低意圖的用戶而言,「跳過」其實是中性的,他們沒有特別想找的歌,所以不喜歡就跳過,也無傷大雅;但是對於高意圖的用戶而言,「跳過」是負面訊號。因此,Spotify 在做用戶行為分析時,也要同時考量用戶的意圖,才能夠分析的更為精準。
(小小工商時間,對這個案例有興趣的話,可以參考我在 2023 年出版的書哦。)
再一個小補充,我們在 Day 6 有聊到一件事:在訓練模型時,只關注模型在資料集上的誤差是不夠的,原因在於即使誤差很小,但是每個案例的重要性可能都不一樣,像是資訊查詢 vs. 導航查詢,這也是依照用戶的意圖不同而區分不同情境。
好了扯遠了,讓我們跳回來看 Lexikon。
即便找到想要的資料集,有時資料科學家還是會想要跟合適的人來討論這些主題,特別是新進員工。因此,他們在 Lexikon 中引入了一個功能,讓用戶能夠搜尋到在某些資料集或特定領域中的「專家」。
而要怎麼選擇誰是專家呢?他們會根據幾個行為來計算分數,包含用戶查詢/擁有的資料集、查看/擁有的儀表板(dashboard)、撰寫的研究報告,或是執行與關鍵字相關的 A/B 測試。這些行為會出現在搜尋結果的列表中,某些行為會有比較大的權重,例如擁有儀表板會比查看儀表板還有更大的權重。
另外,Spotify 還做了一個有趣的小工具。他們內部主要的溝通工具是 Slack,當資料科學家在上面討論資料集時,他們覺得可以透過提供補充資訊來提升溝通效率。因此,他們開發 Lexikon Slack Bot,當用戶在 Slack 上分享 Lexikon 中的資料集連結時,Slack 機器人會提供一個簡單的資料集摘要內容,包含:
我看到這邊真的覺得驚為天人!Spotify 為了提升溝通效率和使用者體驗,竟然連內部員工的溝通效率都考慮到了,這個工具真的非常方便!
自從推出 Lexikon Slack Bot 後,他們發現每週在 Slack 上分享的 Lexikon 連結數量增加 25%,顯示這個功能的廣受好評。
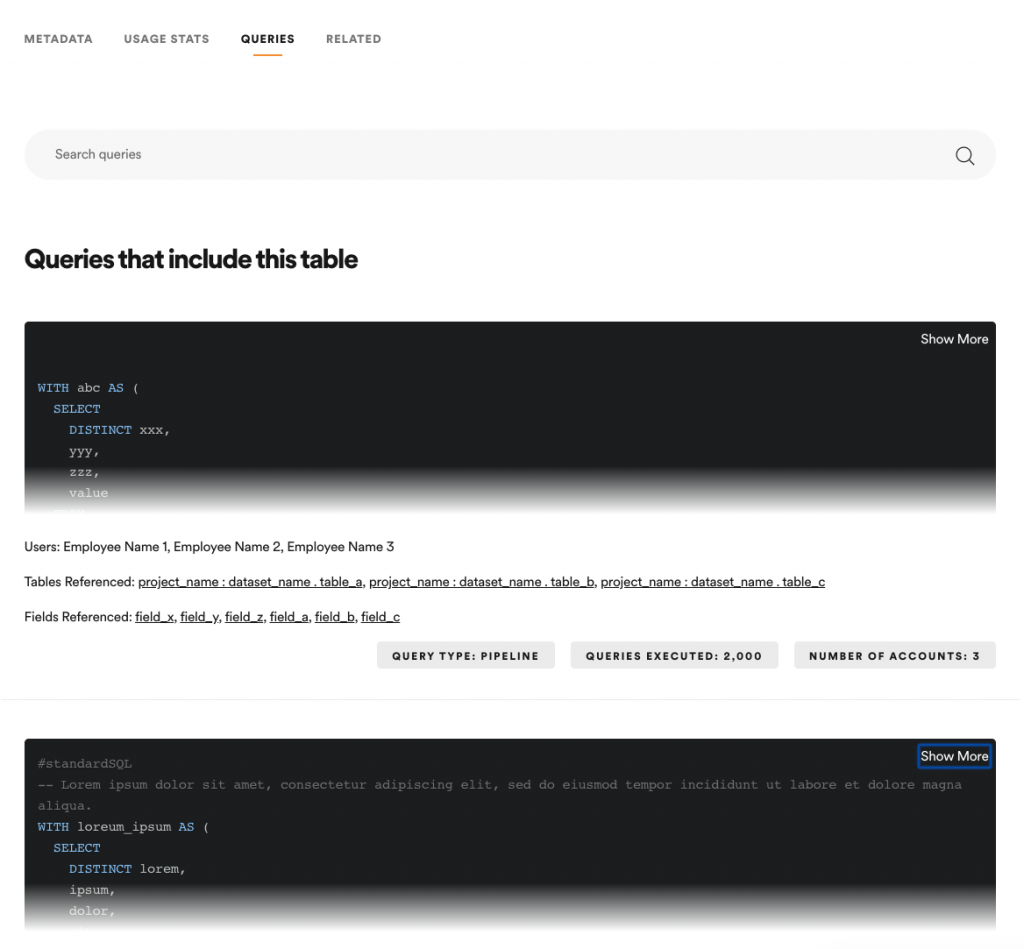
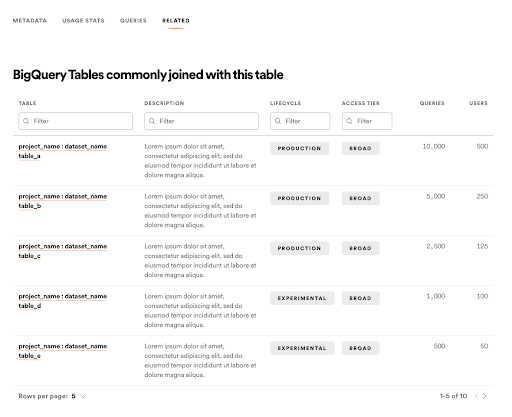
最後,在搜尋到相關資料集之後,Lexikon 也會幫助用戶開始使用這些內容。
簡單來說,他們會提供用戶幾個資訊:
圖片來源:[1]
圖片來源:[1]
圖片來源:[1]
自從 Lexikon 中的資料探索體驗得到改善後,資料科學家對 Lexikon 的採用率從 75% 增加到 95%,成為資料科學家使用的前 5 大工具之一。透過了解用戶意圖、促進知識交流和幫助使用者開始使用資料集,明顯提升 Spotify 資料科學家的資料探索體驗。
資料是所有機器學習專案的基礎,沒有好的資料,就沒有好的食材,即便有再先進的技術,也無法建構出表現優秀的模型。我們在這三天介紹了 Spotify 內部的資料平台,顯示身為音樂串流平台的龍頭,真的有他們厲害之處。除了有各式各樣新穎的演算法之外,他們也非常講求資料蒐集、管理和使用的細節。讓資料科學家得以更無痛地使用資料,打造出更厲害的演算法,推出更厲害的產品功能!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Reference
[1] https://engineering.atspotify.com/2020/02/how-we-improved-data-discovery-for-data-scientists-at-spotify/

 iThome鐵人賽
iThome鐵人賽